Configure Databricks for Unity Catalog
Databricks is a unified, open analytics platform for building, deploying, sharing, and maintaining enterprise-grade data, analytics, and AI solutions. Databricks is used for ETL and for managing security, governance, data discovery among its various other features.
The Calibo Accelerate platform uses Databricks for various operations like data integration, data transformation, and data quality. After you save the connection details for Databricks, you can use it in any of the nodes in a data pipeline, as mentioned earlier.
Prerequisites
The following permissions are required for configuring Databricks:
-
s3:ListBucket
-
s3:PutObject
-
s3:GetObject
-
s3:DeleteObject
-
s3:PutObjectAcl
To access an Amazon S3 bucket from Databricks, you must create an instance profile with read, write, and delete permissions. For detailed instructions on how to create an instance profile, refer to the following link: instance-profile-tutorial.html
To configure the connection details of your Databricks, do the following:
- Sign in to the Calibo Accelerate platform and click Configuration in the left navigation pane.
- On the Platform Setup screen, on the Cloud Platform, Tools & Technologies tile, click Configure.
- On the Cloud Platform, Tools & Technologies screen, in the Data Integration section, click Configure.
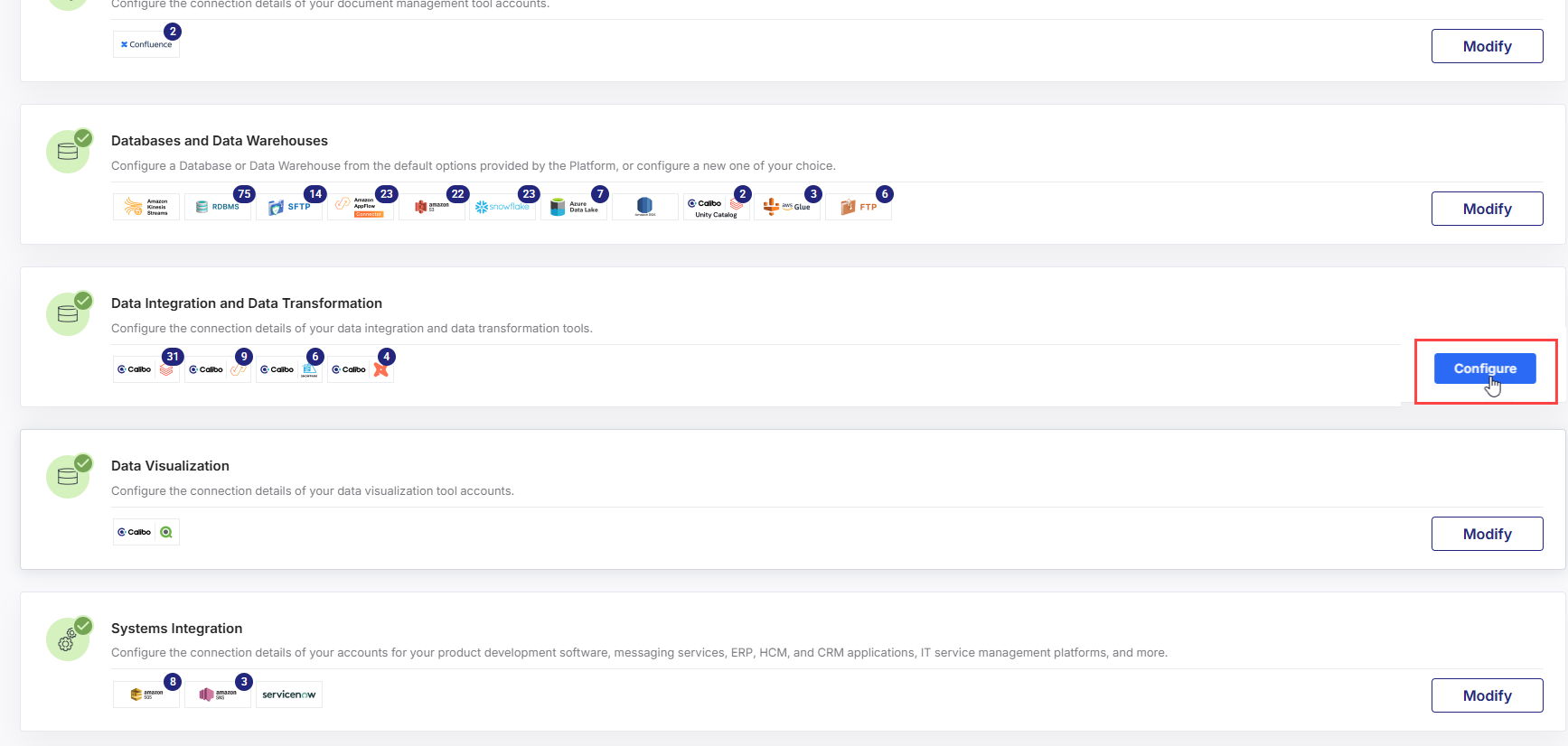 (After you save your first connection details in this section, you see the Modify button here.)
(After you save your first connection details in this section, you see the Modify button here.) - On the Databricks screen, do the following:
In the Details section, provide the following details:
Field Description Name Give a unique name to your Databricks configuration. This name is used to save and identify your specific Databricks connection details within the Calibo Accelerate platform. Description Provide a brief description that helps you identify the purpose or context of this Databricks configuration.
In the Configuration section, provide the following information:
Field Description Workspace URL Provide the URL for the configured Databricks instance.
Select Cloud Provider Select the cloud provider on which the Databricks cluster is deployed.

Note:
You must select the same cloud service provider on which the Databricks cluster is deployed. For example, if Databricks is deployed on Azure, do not select AWS as the cloud service provider.
Depending on the cloud provider on which the Databricks cluster is deployed and how you want to retrieve the credentials to connect to Databricks, do one of the following:
Field Description Connect using Calibo Accelerate Orchestrator Agent Enable this option to resolve your Databricks credentials within your private network via Calibo Accelerate Orchestrator Agent without sharing them with the Calibo Accelerate platform.
If the Cloud Service Provider is AWS, then provide the following details:
Select the Calibo Accelerate Orchestrator Agent for AWS
Secret Name - provide the name with which the secret is stored in AWS Secrets Manager.

If the Cloud Service Provider is Azure, then provide the following details:
Select the Calibo Accelerate Orchestrator Agent for Azure
Vault Name - provide the name of the vault where the secret is stored in Azure Key Vault.

Select Secret Manager If you are not using Calibo Accelerate Orchestrator Agent, you have the following options to store your secrets:
 For Snowflake account hosted on AWS cloud-service provider
For Snowflake account hosted on AWS cloud-service provider- To use the Calibo-managed secrets store, select Calibo and type your Snowflake username and password.

In this case, the user credentials are securely stored in the Calibo-managed secrets store. - To use AWS Secrets Manager, select AWS Secrets Manager. In the Secret Management dropdown list, the AWS Secrets Manager configurations that you save and activate in the Secret Management section on the Cloud Platform, Tools & Technologies screen are listed for selection. Select the configuration of your choice. Provide the Secret Name, Username Key, and the Password Key for the Calibo Accelerate platform to retrieve the secrets for your Snowflake account.

- To use the Calibo-managed secrets store, select Calibo and type your Snowflake username and password.
- For Snowflake account hosted on Azure cloud-service provider
- To use the Calibo-managed secrets store, select Calibo and type your Snowflake username and password.
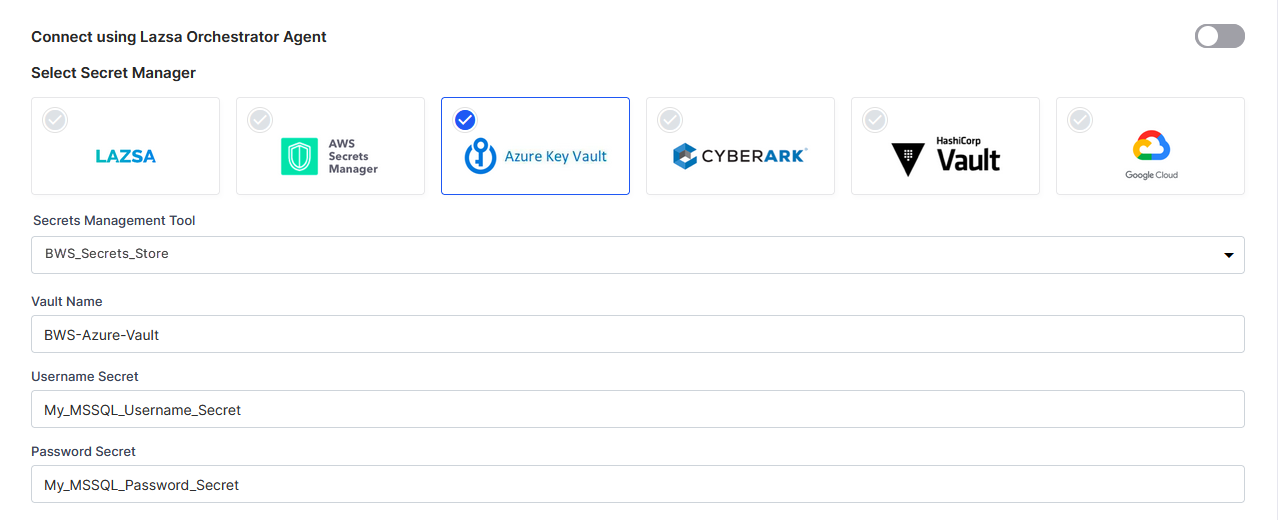 In this case, the user credentials are securely stored in the Calibo-managed secrets store.
In this case, the user credentials are securely stored in the Calibo-managed secrets store. - Select Azure Key Vault from the Secret Management dropdown list. The Azure Key Vault configurations that you save and activate in the Secret Management section on the Cloud Platform, Tools & Technologies screen are listed for selection. Select the configuration of your choice. Provide the Vault Name, Username Secret, and Password Secret for the Calibo Accelerate platform to retrieve the credential values.
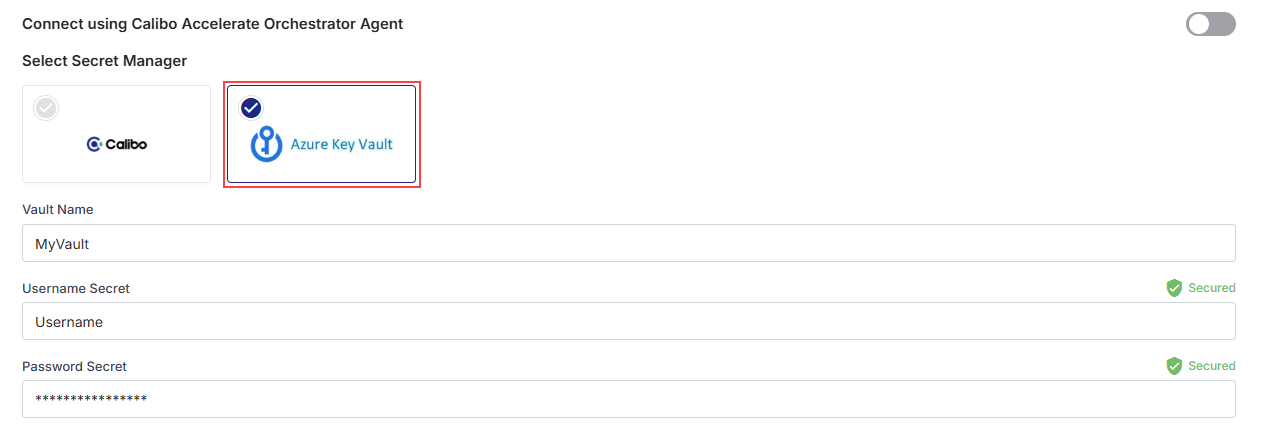
- To use the Calibo-managed secrets store, select Calibo and type your Snowflake username and password.
Databricks API Token Provide the Databricks API token. Test Connection Click Test Connection to verify the provided details and ensure that the Calibo Accelerate platform is able to successfully connect to the configured Databricks instance. In the Databricks Resource Configuration section, provide the following information:
Field Description Organization ID Provide the organization ID. When you log into your Databricks workspace, observe the URL in the address bar of the browser. The numbers following the o= in the URL make up the organization ID.
For example if the URL is https://abcd-teste2-test-spcse2.cloud.databricks.com/?o=2281745829657864#, the organization ID is 2281745829657864.
Cluster Name Do one of the following:
Select an existing cluster from the dropdown list. If you select a Databricks cluster that has unity catalog feature enabled, you will see additional fields related to Unity Catalog settings.
Click + New Cluster to create a new cluster. See Create a Databricks cluster.
Enable Unity Catalog Do one of the following:
If you have selected a Databricks cluster that runs Databricks Runtime version 14.3 LTS or above, but the Unity Catalog feature is not enabled from Databricks, enable this toggle to use the Unity Catalog feature. Once enabled, all the available metastores are displayed in the dropdown list.
If you have selected a Databricks cluster that runs Databricks Runtime version 14.3 LTS or above, and the Unity Catalog feature is enabled from Databricks, no action is required.
Note:
Once the Unity Catalog feature is enabled from Databricks, the toggle is enabled but non-editable from the Calibo Accelerate platform
SQL Warehouse Select a SQL Warehouse that you want to use for this Databricks instance. (This is optional, you can also select a SQL Warehouse when you create a Databricks job using this instance.)
See Add New SQL Warehouse.
Metastore Select the metastore for this Databricks instance. If Unity Catalog is enabled, the metastore is pre-selected and no action is required. Use latest Calibo UTIL version Enable the option if you want the latest Python libraries to be installed on the Databricks cluster.
Init Script Path Init script is required to set up the environment for using Unity Catalog with the Databricks cluster. To create the Init script path, do the following:
Click Download Init Script.
Log on to Databricks and navigate to Catalog in the left navigation pane.
Select the catalog and schema.
In the schema, select Volumes and navigate to init_script.
Click Upload to this volume. Browse to the location where you downloaded the init script in step 1.
After the upload is complete, click Copy path.
Paste the copied path in Init Script Path in Calibo Accelerate.
External Location An external location in a Unity Catalog-enabled Databricks environment is a data storage location such as Amazon S3 or Azure Blob Storage that is linked to Databricks. These locations allow you to access data stored outside of Databricks workspace. Click Manage to view the existing external locations or create a new one. See Create an External Location Workspace Parent Folder Do one of the following:
Provide the name of the parent folder in the Databricks workspace that you are configuring.
Click + New Parent Folder. Provide a Workspace Parent Folder Name and click Create.
Auto Clone Custom Code to Databricks Repos Enable this option if you want your custom code to be automatically cloned to Repository in Databricks. If you disable this option, Calibo Accelerate uploads the custom code to the Repository in Databricks. Secret Scope A secret scope is a collection of secrets that is stored in an encrypted database owned and managed by Databricks Azure. It allows Databricks to use the credentials stored in it locally, eliminating the need to connect to an external secrets management tool, every time a job is run in a data pipeline. You can either use an existing secret scope from the ones already created in Databricks or create a new one. Do one of the following:
Select a secret scope from the dropdown list.
Click + New Secret Scope to create a new secret scope.

Provide a name for the new secret scope and click Create.
- Secure configuration details with a password
To password-protect your Databricks connection details, turn on this toggle, enter a password, and then retype it to confirm. This is optional but recommended. When you share the connection details with multiple users, password protection helps you ensure authorized access to the connection details. Click Save Configuration. You can see the configuration listed on the Data Integration screen.
Add New SQL WarehouseTo create a new SQL warehouse, provide the following information:
SQL Warehouse Name - Provide a unique name for the SQL warehouse that you want to create.
Cluster Size - Select the compute power that you require for the SQL warehouse.
Auto Stop - Enable this option to stop the warehouse if it is idle for the specified number of minutes. Specify the number of minutes of inactivity after which the warehouse is stopped.
Scaling - Select the minimum and maximum number of clusters that the warehouse can scale between for compute power.
Type - Select the type of warehouse to be created from the options given below:
Serverless
Pro
Classic
Tags (Optional) - This feature is optional. Tags are specified as key-value pairs and are used to monitor the cost of cloud resources used in the organization by users or groups. To add a tag, click + Add More. Specify the key name and value for the key.
Type (Optional) - Select the type from Current and Preview.
Click Save to save the configuration details for creating a SQL warehouse.
Create a Unity Catalog-enabled Cluster
To create a new cluster that is unity catalog-enabled, provide the following details:
Cluster DetailsField Description Cluster Name Provide a name for the Databricks cluster that you are creating. Enable Unity Catalog Enable the toggle to use Unity Catalog functionality with this Databricks cluster. Access Mode For a Databricks data integration job, you can select either of the following access modes:
Dedicated - This option allows a single user to run SQL, Python, R, and Scala workloads, with access to data secured in Unity Catalog.
Standard - This option allows multiple users to share the cluster to run SQL, Python, and Scala workloads on data secured in Unity Catalog.
Databricks Runtime Version Select a version based on the type of job for which you want to use the Databricks cluster.
Worker Type Select the processing capacity that you need. This is based on the use case you are trying to achieve. Workers Number of worker nodes. This depends on the kind of cluster you want to create. For example, a multi-node cluster requires a greater number of workers. Enable Autoscaling Turn on this toggle to control the infrastructure costs. If you enable this option, and provide values for Min Workers and Max Workers, the infrastructure costs begin at minimum workers and can scale up to maximum workers depending on the requirement. Terminate after below minutes of inactivity Use this option to control the infrastructure costs. Provide a value in minutes. If the Databricks cluster is inactive for the specified minutes, it is automatically terminated. Use latest Calibo UTIL version Enable this option to use the required utility. Cloud Infrastructure DetailsField Description First on Demand Lets you pay for the compute capacity by the second. Availability Availability zone for a cluster. The instance type you want may be available only in certain zones. Zone Select a zone from the available options. Instance Profile ARN Instance Profiles allow you to access your data from Databricks clusters. Specify the Instance Profile ARN. EBS Volume Type Databricks provisions EBS volumes by default, for efficient functioning of the cluster. You can specify the type of EBS volume, the EBS volume count and the EBS volume size. EBS Volume Count EBS Volume Size Additional DetailsField Description Spark Config You can fine-tune your spark jobs by providing custom Spark configuration properties. For more information see Spark configuration properties.
Enter the configuration properties as one key-value pair per line.
Environment Variables You can add the required environment variables.
Environment variables are used to configure various aspects of the behavior of the Databricks cluster and environment. For example: The Python version to use, number of worker instances to start on each worker node, location of the Apache Spark installation on the cluster nodes, the logging level to be set for the cluster and so on.
Logging Path When you create a cluster, you specify the location where the logs for the Spark driver node, worker nodes, and events are stored.
Select the destination from the following options:
DBFS
S3
Log Level Select the level for logging that you want to set for this cluster. Choose from the following options:
ALL
DEBUG
ERROR
FATAL
INFO
OFF
TRACE
WARN
NONE
Init Scripts Set the destination and the path of the location where the init scripts for the cluster are stored. Init scripts customize the initialization process of the cluster by executing specified commands or scripts when the cluster spins up. The scripts perform various tasks like configuring the cluster environment, installing additional software packages, setting environment variables and so on. Specify the destination and the actual path for the init scripts:
Destination - Select from the following options:
Workspace
DBFS
S3
Init script path - Specify the actual path on the selected destination.
Type A table is created with the options that are selected in the previous step and the information is summarized as shown below:
Type File Path Region Delete dbfs dbfs:/logging - delete icon File Path Region Tags Tags allow you to monitor the cost of cloud resources used by various group within your organization. The tags that you add as key-value pairs are applied by Databricks to cloud resources like VMs, disk volumes and so on.
To add a tag, provide the following information:
Tag - Provide a name for the tag.
Value - Provide a value for the tag.
Create an external location
Note:
If you are creating an external location on a Unity Catalog-enabled Databricks instance that is deployed on Azure, ensure that you have the CREATE EXTERNAL LOCATION permission.
-
On the Databricks cluster configuration under External Location, click Manage.
-
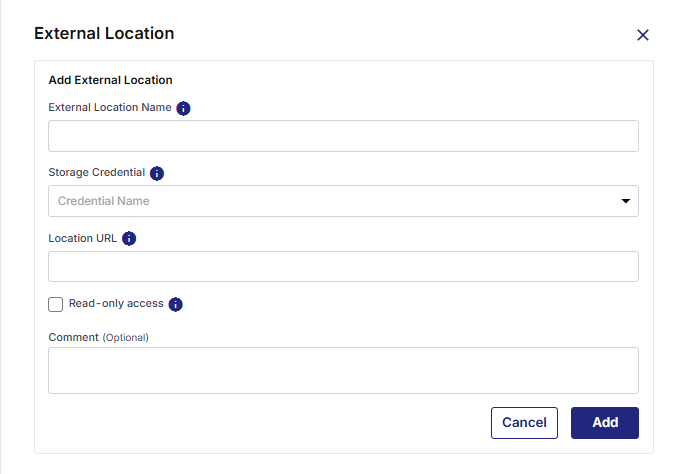
On the External Location side drawer, click Add External Location and provide the following information:
-
External Location Name - A name for the external location that you want to create.
-
Storage Credential - Credentials that authorize access to the external storage location.
-
Location URL - The path of the external storage location.
-
Read-only Access - Click this option to enable read-only access to users to this external storage location.
-
Comment - Add any comments about this external storage location.
-
Click Add.
The newly created external location gets listed in the table.
-