Data Lake Adapters
A data lake is a centralized repository designed to store, process, and secure a vast amount of structured, semistructured, and unstructured data. Data lakes provide organizations with the capability to store diverse types of data. One of the key features of a data lake is its scalability, which allows organizations to store and manage massive volumes of data. Data lakes often use distributed computing frameworks to process and analyze data in parallel, enabling faster insights and analytics. Data lakes are suitable for various use cases such as big data analytics, machine learning, and data exploration.
Currently, the Calibo Accelerate platform supports Amazon S3 and Snowflake data lakes. You can extend the functionality to support additional data lakes.
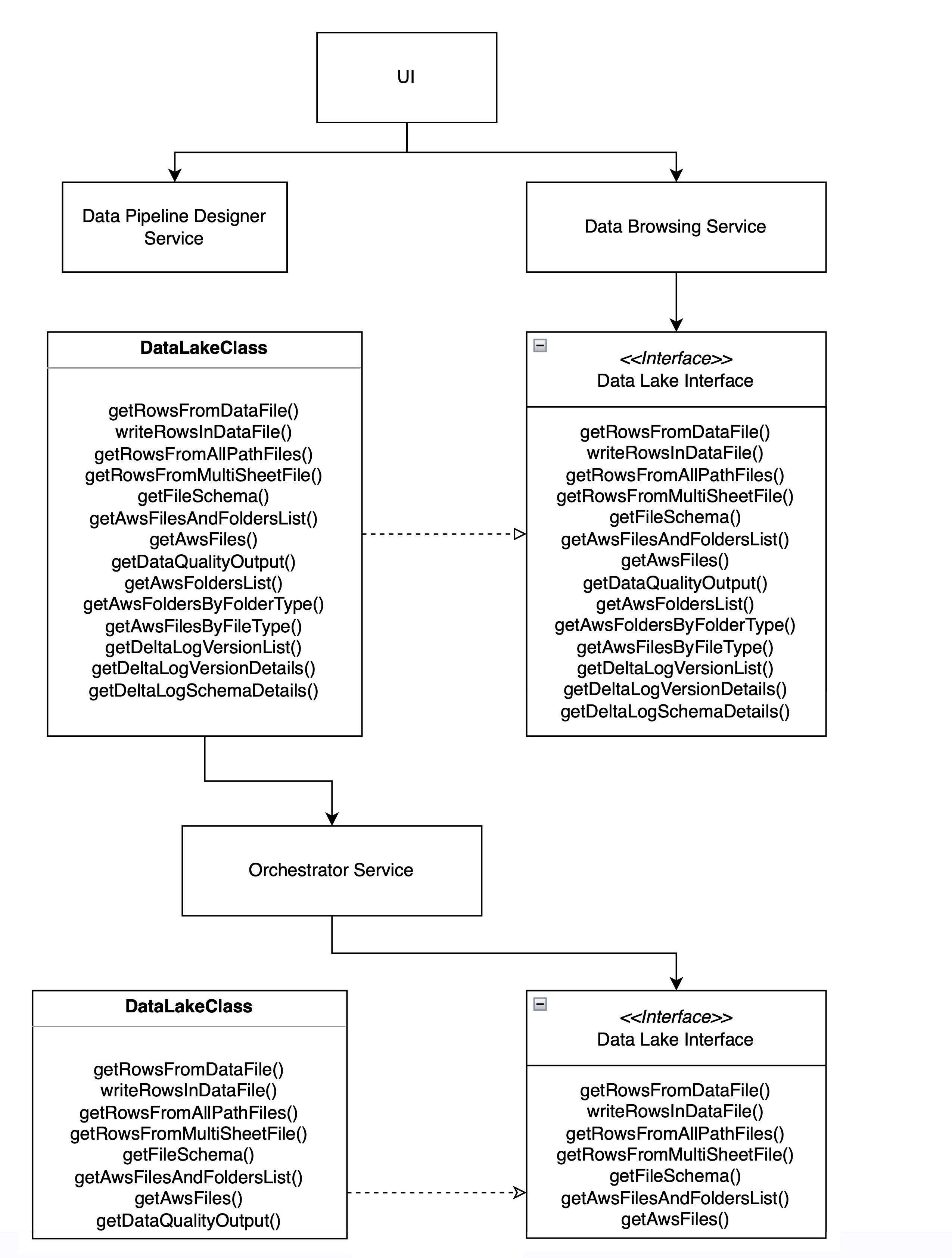
APIs and Interfaces
You can use the following APIs for extending the functionality of data lake as required.
| getRowsFromFile () |
|
| GetRowsFromAllPathFiles () |
|
| GetRowsFromMultisheetFile () |
|
| GetFileSchema () |
|
| GetFileAndFolderList () |
|
| GetDataQualiltyOutput () |
|
| GetFolderList () |
|
| GetDeltaLogVersionList () |
|
| GetDeltaLogVersionDetails () |
|
| GetDeltaLogSchemaDetails () |
|
| What's next?Data Quality Adapters |