Add a New Crawler
Purpose
Adding a new crawler for Azure Blob Storage to the Calibo Accelerate platform.
Azure blob is one of the Object storages where different types of files such as CSV, TSV, Excel etc. are stored. The metadata and data format of file objects is different from traditional RDBMS systems and hence RDBMS crawlers won't support such file systems.
To support such storage, new crawlers must be developed and integrated with the Calibo Accelerate platform.
The diagram below shows the related microservices. Implementation of any new crawler will impact these set of services.
| Microservice | Change Impact |
|---|---|
| plf-elab-service | Configuration changes |
| plf-configuration-service | Configuration changes |
| plf-data-pipeline-designer | Code changes |
| plf-common-orchestrator | Code changes |
Microservices impacted by Crawler development

In the Calibo Accelerate platform ecosystem, we have microservices that deal with the functionality of the crawlers. For developing any crawlers say AzureCrawler, the implementation of the interfaces exposed, need to be developed and added to the respective folders for compilation.
Once the developed classes are compiled with the service named plf-data-pipeline-designer, then the integration of the crawler has to be to be done with the platform.
Integration involves creating settings and entries in other modules of the platform for consumption of the newly developed code. Adjustments in plf-elab-service and plf-configuration-service to be added for consuming the new crawler.
Similarly, if the developed crawler needs to be added to the Calibo Accelerate orchestrator framework, then in addition to mentioned details, the crawler classes need to be compiled with plf-common-orchestrator.
In the above diagram, AzureCrawler is the developed piece of code extended from plf-data-pipeline-designer service interface and compiled with different components of the Calibo Accelerate platform.
Steps for adding Azure Blob Storage as a crawler
You need to make the following changes to the different microservices in order to add Azure Blob Storage as a crawler.
| Steps | Examples | Action |
|---|---|---|
| Microservice: plf-elab-service This service is responsible for orchestrating the business logic of the platform dealing with product portfolios and products. |
||
| Add entry to the: com.calibo.platform.elab.enums.ProviderEnum |
Copy
|
Action performed by Calibo Accelerate team. |
| Microservice: plf-data-pipeline-designer This service is responsible for all business logic related to data management of the platform like data crawlers, data visualizers, data catalog, etc. |
||
| Create an entry to the crawler utility class in package: com.calibo.platform.dpd.util |
Copy
|
|
| Implement the AzureBlobCrawler under package: com.calibo.platform.dpd.service.impl.crawler |
The AzureBlobCrawler will implement all the methods of interface com.calibo.platform.dpd.repository. Copy
|
Action performed by Adapter Development Team |
| Microservice: plf-configuration-service This service is responsible for managing the configurations of the platform like user settings, tool settings, tenant settings, etc. |
||
| Insert DB entries under databases and data stores | INSERT INTO `setting` (`name`, `description`, `config_code`, `section`, `sub_section`, `config_version`, `selected`, `default`, `provider_code`, `logo`, `version`, `created_by`, `created_on`, `updated_by`, `updated_on`) VALUES (‘Azure Blob’, ‘Azure Blob is an open-source x technology management system.', 'DATA_STORES', NULL, NULL, NULL, false, false, AZURE_BLOB, '/techx.png', 0, 'system’, now(), 'system’, now()) | Action performed by Calibo Accelerate team. |
| Add AZURE_BLOB in the enum com.calibo.platform.core.enums.ProviderEnum |
Copy
|
Action performed by Calibo Accelerate team. |
|
Microservice: plf-common-orchestrator This is a Calibo Accelerate agent that deals with the execution of data related activities with the unexposed tools from the client side. This component helps in abstracting the tools defined and added on the client side from the platform. |
||
| Implement the AzureBlobCrawler under package com.calibo.platform.common.service |
The AzureBlobCrawler will implement all the methods of interface com.calibo.platform.common.service. Copy
|
Action performed by Adapter Development Team |
Compile all the above services and deploy them in the ecosystem to start the integration process.
Deployment process of the impacted microservices
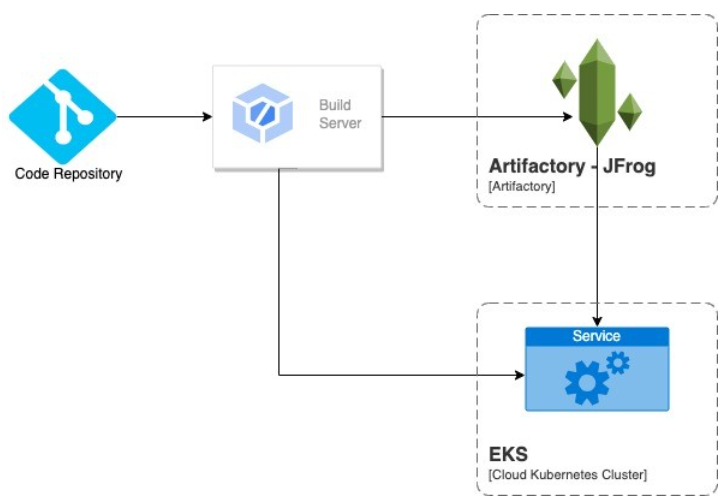
The developed code once placed in the proper packages of the services has to be pushed to the source code repositories with proper approval process. As the new code is pushed to the source code repository, the build server detects the changes, triggers auto build and deploys jobs.
The build server pulls the changes on the specific repositories and branches, builds the code, which in turn prepares the packaged jar to be kept at the artifactory.
The build server then triggers the deployment on the specific environment from the packaged jar.
Steps to verify the Azure Blob crawler in the Calibo Accelerate platform
The newly developed crawler must be added as a data store in Cloud Platform, Tools & Technologies under the Configuration section.
| Steps | Details |
|---|---|
| Log in to the Calibo Accelerate platform |
|
| Get a list of the supported data types |
Fetch a list of supported data types by using the following API. The response provides all the types of datastores along with the new data store added to be consumed in crawler. Copy
|
| Add the instance of new data type to be consumed in the Platform for crawling |
Trigger the following API to add an instance of AZURE_BLOB in platform configuration. In the payload, “attributes” is a list of key value pairs which is required to connect to the technology for performing the required operations. Copy
|
| Fetch the instances that are added to be consumed in the crawler |
Retrieve the newly added datastore by using the following API: Copy
|
| Add a new crawler using the new instance added in Configuration |
Add supported crawlers using existing configuration by using the following API: Copy
|
| Fetch a list of crawlers added to the Platform |
Fetch a list of all the added crawlers by using the following API: Copy
Response is a list of objects: Copy
[ |
| Execute the recently added crawler |
Execute the crawler using the following API: Copy
curl 'https://lazsa-dis.calibo.com/datapipeline/crawlers/run?crawlerId=aa10a268-901e-4c8f-a1ed-7c6c6ff6d935' \ |
| Fetch status of the executed crawler |
Copy
Response is details of the crawler Copy
The status attribute of the response is the status of the crawler run. |
| Analyze the crawled data from the crawler |
The crawler provides data in the standard format and can be checked using the following API: Copy
Response is list of details of the crawled data. Copy
|
| What's next? Integrate a New Technology in an Existing Crawler Category |