Data Ingestion using Databricks Autoloader
Calibo Accelerate platform currently supports data ingestion from Amazon S3 data source into Unity Catalog data lake using Databricks Autoloader feature.
Databricks Autoloader currently supports the following file formats using S3 as a data source:
-
JSON
-
CSV
-
Parquet
What is Databricks Autoloader and how does it work?
Databricks Autoloader incrementally processes data files as they arrive in cloud storage. It provides a structured streaming source called cloudFiles. This source automatically processes files as they arrive.
As files are discovered, their metadata is persisted in a scalable key-value store (RocksDB) in the checkpoint location of the Autoloader pipeline. This key-value store ensures that data is processed just once. In case of failures Autoloader resumes from where it left off with information stored in the checkpoint location, eliminating the need to maintain the state manually.
Creating a data integration job
Complete the following steps to create the Databricks data integration job using S3 as source and Unity Catalog as target.
-
Create a data pipeline using the following nodes:

-
Configure the source and target nodes.

Note:
While configuring the S3 source node, make sure to select a folder and not a file. If you select a file, an error is shown, and the job creation cannot be completed.
-
Complete the following steps to create the job:
 Job Name
Job Name
Provide job details for the data analyzer job:
-
Template - Based on the source and destination that you choose in the data pipeline, the template is automatically selected.
-
Job Name - Provide a name for the data analyzer job.
-
Node Rerun Attempts - Specify the number of times the pipeline rerun is attempted on this node of the pipeline, in case of failure. The default setting is done at the pipeline level. You can change the rerun attempts by selecting 1, 2, or 3.
-
Fault tolerance - Select the behaviour of the pipeline upon failure of a node. The options are:
-
Default - Subsequent nodes should be placed in a pending state, and the overall pipeline should show a failed status.
-
Skip on Failure - The descendant nodes should stop and skip execution.
-
Proceed on Failure - The descendant nodes should continue their normal operation on failure.
-
Source
In this stage, the source details are auto-populated. You can select the Autoloader parameters according to your use case.
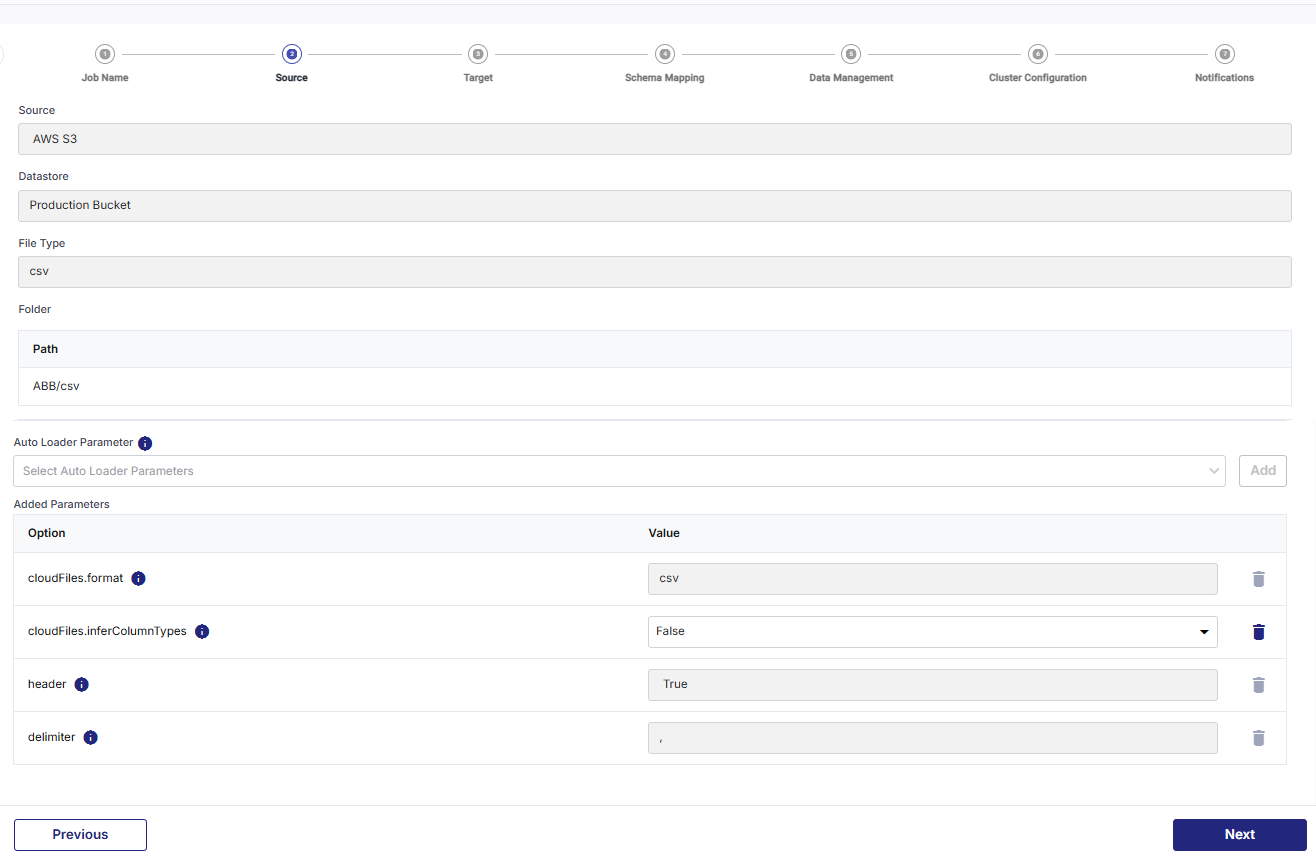
The following fields are auto-populated:
-
Source
-
Datastore
-
File Type
-
Folder and Path
-
Autoloader - Select the parameters based on your use case from the options below. By default, some parameters are pre-selected. You can either choose additional parameters from the three categories or proceed with the default selection.
By default, the following parameters are selected:
-
cloudFiles.format
-
cloudFiles.InferColumnTypes
This parameter decides whether to infer exact column types when leveraging schema inference. If this parameter is set to True, then the InferSourceSchema toggle is turned on in Schema Mapping.
-
header
-
delimiter
-
-
True
-
False
-
True
-
False
-
True
-
False
-
True
-
False
-
True
-
False
GENERIC OPTIONS
Settings that are applicable to the autoloading process and are not specific to any file format.
Sr.No. Parameter Type Description Values 1 ignoreCorruptFiles Boolean Decides whether to ignore corrupt files. If set to true, the Spark jobs continue to run when it encounters corrupted files and returns the contents that has been read. Default value is false.
2 ignoreMissingFiles Boolean Decides whether to ignore missing files. If set to true, the Spark jobs continue to run when it encounters missing files and returns the content that has been read. Default value: false for Autoloader
true for COPY INTO
3 modifiedAfter Date Ingests files that have a modification timestamp after the provided timestamp. YYYY:MM:DD HH:MM:SS Default value – none 4 modifiedBefore Date Ingests files that have a modification timestamp before the provided timestamp. YYYY:MM:DD HH:MM:SS Default value – None 5 pathGlobFilter A potential glob pattern to provide for choosing files. Equivalent to PATTERN in COPY INTO. pathGlobFilter can be used in read_files. Default value: None COMMON FORMAT OPTIONS
These are settings that are commonly applicable to any file format that is used for data ingestion.
Sr.No. Parameter Type Description Values 1 cloudFiles.allowOverwrites Boolean Decides whether to allow input directory file changes to overwrite existing data. Default value is false.
2 cloudFiles.schemaEvolutionMode Boolean The mode for evolving the schema as new columns are discovered in the data. By default, columns are inferred as strings when inferring JSON datasets. - Default value: "addNewColumns" when a schema is not provided. Otherwise, the value is “none".
3 cloudFiles.includeExistingFiles Date Decides whether to include existing files in the stream processing input path or to only process new files arriving after initial setup. This option is evaluated only when you start a stream for the first time. Changing this option after restarting the stream has no effect. Default value - False
4 cloudFiles.partitionColumns Date A comma separated list of Hive style partition columns that you would like inferred from the directory structure of the files. Hive style partition columns are key value pairs combined by an equality sign such as <base-path>/a=x/b=1/c=y/file.format. In this example, the partition columns are a, b, and c. By default, these columns will be automatically added to your schema if you are using schema inference and provide the <base-path> to load data from. If you provide a schema, Auto Loader expects these columns to be included in the schema. If you do not want these columns as part of your schema, you can specify "" to ignore these columns. Default value – None 5 cloudFiles.backfillInterval Interval String Auto Loader can trigger asynchronous backfills at a given interval, e.g. 1 day to backfill once a day, or 1 week to backfill once a week. File event notification systems do not guarantee 100% delivery of all files that have been uploaded therefore you can use backfills to guarantee that all files eventually get processed, available in Databricks Runtime 8.4 (unsupported) and above. Allowed minimum value is 1.
Default value: None
6 cloudFiles.validateOptions Boolean Whether to validate Auto Loader options and return an error for unknown or inconsistent options. Default value - False
7 cloudFiles.schemaHints String Schema information that you provide to Auto Loader during schema inference. FORMAT SPECIFIC OPTIONS
These are settings specific to the file format that is used for loading data. The settings provide fine control over how data is read from the format.
JSON
Sr.No. Parameter Type Description Values 1 allowBackslashEscapingAnyCharacter Boolean Whether to allow backslashes to escape any character that succeeds it. If not enabled, only characters that are explicitly listed by the JSON specification can be escaped. Default value - false 2 allowComments Boolean Whether to allow the use of Java, C, and C++ style comments ('/', '*', and '//' varieties) within parsed content or not. Default value - false 3 allowNonNumericNumbers Boolean Whether to allow the set of not-a-number (NaN) tokens as legal floating number values. Default value - true 4 allowNumericLeadingZeros Boolean Whether to allow integral numbers to start with additional (ignorable) zeroes (for example, 000001). Default value - false 5 allowSingleQuotes Boolean Whether to allow use of single quotes (apostrophe, character '\') for quoting strings (names and String values). Default value - true 6 allowUnquotedControlChars Boolean Whether to allow JSON strings to contain unescaped control characters (ASCII characters with value less than 32, including tab and line feed characters) or not. Default value - false 7 allowUnquotedFieldNames Boolean Whether to allow use of unquoted field names (which are allowed by JavaScript, but not by the JSON specification). Default value - false 8 badRecordsPath String The path to store files for recording the information about bad JSON records. Default value - None 9 columnNameOfCorruptRecord String The column for storing records that are malformed and cannot be parsed. If the mode for parsing is set as DROPMALFORMED, this column will be empty. Default value - _corrupt_record 10 dateFormat String The format for parsing date strings. Default value - yyyy-MM-dd 11 dropFieldIfAllNull Boolean Whether to ignore columns of all null values or empty arrays and structs during schema inference. Default value - false 12 encoding or charset String The name of the encoding of the JSON files. See java.nio.charset.Charset for list of options. You cannot use UTF-16 and UTF-32 when multiline is true. Default value - UTF-8 13 inferTimestamp Boolean Whether to try and infer timestamp strings as a TimestampType. When set to true, schema inference might take noticeably longer. You must enable cloudFiles.inferColumnTypes to use with Auto Loader. Default value - false 14 lineSep String A string between two consecutive JSON records. Default value - None, which covers \r, \r\n, and \n 15 mode String Parser mode around handling malformed records. One of 'PERMISSIVE', 'DROPMALFORMED', or 'FAILFAST'. Default value - PERMISSIVE 16 multiLine Boolean Whether the JSON records span multiple lines. Default value - false 17 prefersDecimal Boolean Attempts to infer strings as DecimalType instead of float or double type when possible. You must also use schema inference, either by enabling inferSchema or using cloudFiles.inferColumnTypes with Auto Loader. Default value - false 18 primitivesAsString Boolean Whether to infer primitive types like numbers and booleans as StringType. Default value - false 19 timestampFormat String The format for parsing timestamp strings. Default value - yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX] Parquet
Sr.No. Parameter Type Description Values 1 datetimeRebaseMode String Controls the rebasing of the DATE and TIMESTAMP values between Julian and Proleptic Gregorian calendars. Allowed values: EXCEPTION, LEGACY, and CORRECTED. Default value - LEGACY 2 int96RebaseMode String Controls the rebasing of the INT96 timestamp values between Julian and Proleptic Gregorian calendars. Allowed values: EXCEPTION, LEGACY, and CORRECTED. Default value - LEGACY CSV
Sr.No. Parameter Type Description Values 1 charToEscapeQuoteEscaping Character The character used to escape the character used for escaping quotes. \ 2 columnNameOfCorruptRecord String The column for storing records that are malformed and cannot be parsed. If the mode for parsing is set as DROPMALFORMED, this column will be empty. Default value - _corrupt_record 3 comment Character Defines the character that represents a line comment when found in the beginning of a line of text. Use '\0' to disable comment skipping. Default value - '\u0000' 4 dateFormat String The format for parsing date strings. Default value -
" "
5 emptyValue String String representation of empty value. Default value -
" "
6 enforceSchema Boolean Whether to forcibly apply the specified or inferred schema to the CSV files. Default value - True 7 escape Character The escape character to use when parsing the data. Default value '\' 8 ignoreLeadingWhiteSpace Boolean Whether to ignore leading whitespaces for each parsed value. Default value - False 9 ignoreTrailingWhiteSpace Boolean Whether to ignore trailing whitespaces for each parsed value. Default value - False 10 lineSep String A string between two consecutive JSON records. 11 maxCharsPerColumn Integer Maximum number of characters expected from a value to parse. 12 mode String Parser mode around handling malformed records. Default value - Permissive 13 multiLine Boolean Whether the CSV records span multiple lines. Default value - False 14 nullValue String String representation of a null value Default value -
" "
15 quote Character The character used for escaping values where the field delimiter is part of the value. Default value -
"
16 skipRows Integer The number of rows from the beginning of the CSV file that should be ignored. Default value - 0 17 unescapedQuoteHandling String The strategy for handling unescaped quotes. Allowed options: STOP_AT_CLOSING_QUOTE: If unescaped quotes are found in the input, accumulate the quote character and proceed parsing the value as a quoted value, until a closing quote is found. BACK_TO_DELIMITER: If unescaped quotes are found in the input, consider the value as an unquoted value. This will make the parser accumulate all characters of the current parsed value until the delimiter defined by sep is found. If no delimiter is found in the value, the parser will continue accumulating characters from the input until a delimiter or line ending is found. STOP_AT_DELIMITER: If unescaped quotes are found in the input, consider the value as an unquoted value. This will make the parser accumulate all characters until the delimiter defined by sep, or a line ending is found in the input. SKIP_VALUE: If unescaped quotes are found in the input, the content parsed for the given value will be skipped (until the next delimiter is found) and the value set in nullValue will be produced instead. RAISE_ERROR: If unescaped quotes are found in the input, a TextParsingException will be thrown. Default value - STOP_AT_DELIMITER Target
In this stage, you can select the schema for the target, map the source data to target tables, and enable object tagging and add tags.

-
Datastore - This field is auto-populated, based on the configuration of the target node.
-
Catalog Name - This field is auto-populated, based on the configuration of Unity Catalog.
-
Schema Name - You can select a schema.
-
Object Tagging - Enable this toggle if you want to add tags.
-
SQL Warehouse - Select a SQL Warehouse, the existing tags are fetched.
-
-
Map source data to target tables - Map the source file to a target table.
-
Source - Select a source file from the dropdown.
-
Target Table - Select a target table to map with the selected source file. You can either select an existing table or create a new one.
-

Note:
For an existing target table, the cloudFiles.InferColumnTypes parameter is ignored, if selected.
-
Temporary File Location (Schema) - Select a schema from the dropdown list.
A path is created for schema and checkpoint location in two separate folders, using a combination of schema, table name and Job ID.
-
Click Map Table.
-
In the table that shows the source and target mapping, click Add Tags. Tags are added as key value pairs.
-
Key - Add a key for the tag.
-
Value - Add a value for the tag.
-
Click Save.
-
-
Click Next.
Schema Mapping
In this stage, you must provide the schema mapping details for all the mapped tables from the previous step.
-
Mapped Data - Select a mapping.
-
Infer Source Schema - This toggle is automatically turned on if the parameter cloudFiles.InferColumnTypes is set to true in the source stage.
-
Evolve Schema - This toggle if turned on allows the addition of columns in the target table if a column is added to the source table. If this toggle is turned off and there is schema change in the source table, then the job fails.
-
Filter columns from selected table - In this section, deselect the columns that you want to exclude from the mapping. Select a constraint to run on the source column. Only if the constraint is fulfilled, the column is mapped to the target.
-
SET NOT NULL - this means that the column should not have a null value.
-
CHECK - Select a boolean expression and value for the condition.
-
-
Continue job run even if constraints are not met - This toggle ensures that the job run is continued even if a constraint is not met.
-
Add Custom Columns - Enable this toggle if you want to add custom columns.
-
Column - Provide a column name.
-
Type - Select a type from the following options:
Type Description Static Parameter Provide a static value. The custom column is checked for that value. System Parameter Select a custom column from the dropdown list. The custom column is checked for the value. Generated Parameter Add a SQL expression to concatenate the value from the selected column and add it to the custom value. -
Click Add Custom Column.
-
Click Add Schema Mapping.
-
Click Next.
A summary is displayed on the next screen. You can perform the following operations:
-
View Details
-
Edit
-
Delete
Data Management
In this stage, you select the operations to perform on the data. You must provide data management details for all the mapped tables.
-
Mapped Data - Select the mapped table for which you want to select data operations.
Data Management for Mapped Tables
-
Operation Type - Select a data operation to be performed from the following options:
-
Append
-
Merge
-
-
Enable Partitioning - Enable this operation to use partitioning to manage data in a better way. Select one of the following options:
-
Data Partition
-
Date Partition
-
-
Final Table - The final table is created based on the selected option for data partitioning.
Click Next.
Cluster Configuration
You can select an all-purpose cluster or a job cluster to run the configured job. In case your Databricks cluster is not created through the Calibo Accelerate platform and you want to update custom environment variables, refer to the following:
Updating Custom Variables for a Databricks Cluster
All Purpose Clusters
Cluster - Select the all-purpose cluster that you want to use for the data integration job, from the dropdown list.
Job Cluster
Cluster Details Description Choose Cluster Provide a name for the job cluster that you want to create. Job Configuration Name Provide a name for the job cluster configuration. Databricks Runtime Version Select the appropriate Databricks version. Worker Type Select the worker type for the job cluster. Workers Enter the number of workers to be used for running the job in the job cluster.
You can either have a fixed number of workers or you can choose autoscaling.
Enable Autoscaling Autoscaling helps in scaling up or down the number of workers within the range specified by you. This helps in reallocating workers to a job during its compute-intensive phase. Once the compute requirement reduces the excess number of workers are removed. This helps control your resource costs. Cloud Infrastructure Details First on Demand Provide the number of cluster nodes that are marked as first_on_demand.
The first_on_demand nodes of the cluster are placed on on-demand instances.
Availability Choose the type of EC2 instances to launch your Apache Spark clusters, from the following options:
-
Spot
-
On-demand
-
Spot with fallback
Zone Identifier of the availability zone or data center in which the cluster resides.
The provided availability zone must be in the same region as the Databricks deployment.
Instance Profile ARN Provide an instance profile ARN that can access the target Amazon S3 bucket. EBS Volume Type The type of EBS volume that is launched with this cluster. EBS Volume Count The number of volumes launched for each instance of the cluster. EBS Volume Size The size of the EBS volume to be used for the cluster. Additional Details Spark Config To fine tune Spark jobs, provide custom Spark configuration properties in key value pairs. Environment Variables Configure custom environment variables that you can use in init scripts. Logging Path (DBFS Only) Provide the logging path to deliver the logs for the Spark jobs. Init Scripts Provide the init or initialization scripts that run during the start up of each cluster. -
-
Select All
-
Node Execution Failed
-
Node Execution Succeeded
-
Node Execution Running
-
Node Execution Rejected
You can configure the SQS and SNS services to send notifications related to the node in this job. This provides information about various events related to the node without actually connecting to the Calibo Accelerate platform.
| SQS and SNS |
|---|
| Configurations - Select an SQS or SNS configuration that is integrated with the Calibo Accelerate platform. |
|
Events - Enable the events for which you want to enable notifications: |
| Event Details - Select the details of the events from the dropdown list, that you want to include in the notifications. |
| Additional Parameters - Provide any additional parameters that are to be added in the SQS and SNS notifications. A sample JSON is provided, you can use this to write logic for processing the events. |
| What's next? Data Issue Resolver using Unity Catalog |