Data Ingestion of Unstructured Data from SFTP or FTP into Unity Catalog
Calibo Accelerate supports the data ingestion of unstructured data into Unity Catalog, using Databricks for data integration. Using managed volumes for storing unstructured data brings benefits like scalability, performance optimization, and simplified management.
The data ingestion pipeline for unstructured data has the following nodes:
SFTP/FTP (data source) > Databricks (data integration) > Unity Catalog (data lake)

To create a data ingestion job for unstructured data
-
Log on to the Calibo Accelerate platform and navigate to Products.
-
Select a product and feature. Click the Develop stage of the feature and navigate to Data Pipeline Studio.
-
Create a pipeline with the following nodes:
-
Data Source - FTP/SFTP
-
Data Integration - Databricks (Unity Catalog enabled)
-
Data Lake - Unity Catalog (Data Lakehouse)
-
-
Configure the data source and data lake nodes and connect them to the data integration node.
Complete the following steps to create a data ingestion job for unstructured data:
Provide job details for the data integration job:
-
Template - Based on the source and destination that you choose in the data pipeline, the template is automatically selected.
-
Job Name - Provide a name for the data integration job.
-
Node rerun Attempts - Specify the number of times the pipeline rerun is attempted on this node of the pipeline, in case of failure. The default setting is done at the pipeline level. You can change the rerun attempts by selecting 1,2, or 3.
-
Fault Tolerance - Define the behavior of the node upon failure, where the descendent nodes can either stop and skip execution or can continue their normal operation. The available options are:
-
Default - If a node fails, the subsequent nodes go into pending state.
-
Proceed on Failure - If a node fails, the subsequent nodes are executed.
-
Skip on Failure - If a node fails, the subsequent nodes are skipped from execution.
For more information, see Fault Tolerance of Data Pipelines.
-
-
Source - This field is automatically populated, depending on the data source node configured and added in the pipeline.
-
Datastore - This field is automatically populated, depending on the configured datastore that you added in the pipeline.
-
File format - In case of unstructured data, Other is selected. For other sources, this field is automatically populated.
-
File - The path of the selected file.
Click Next.
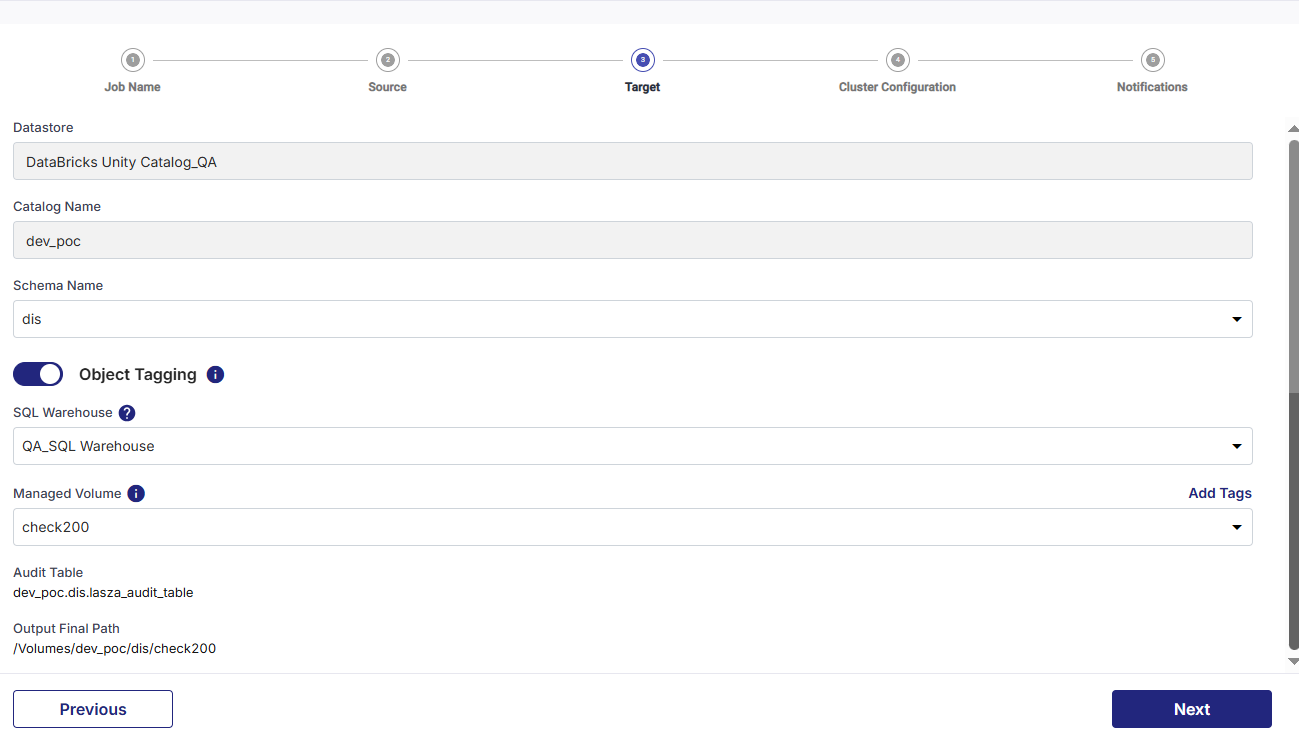
Provide the following information for the target stage:
-
Datastore - This field is automatically populated, depending on the target node configured and added in the pipeline.
-
Catalog Name - This field is automatically populated, depending on the catalog selected for the selected Unity Catalog.
-
Schema Name - Select the schema from the dropdown list.
-
Object Tagging - Enable this option to add tags to the objects of the target.
-
SQL Warehouse - Select a SQL warehouse from the dropdown list.
-
-
Managed Volume - Select a managed volume. If tags are enabled, they are applied to this managed volume. If the managed volume is changed in the job configuration, the tags are deleted. You must create new tags for the new managed volume.
-
Audit Table - This is the path of the audit table.
-
Output Final Path - This is the final path where the output is loaded. This path is created based on the selected managed volume.
Click Next.
You can select an all-purpose cluster or a job cluster to run the configured job. In case your Databricks cluster is not created through the Calibo Accelerate platform and you want to update custom environment variables, refer to the following:
Updating Custom Variables for a Databricks Cluster
Cluster - Select the all-purpose cluster that you want to use for the data integration job, from the dropdown list.
Note:
If you do not see a cluster configuration in the dropdown list, it is possible that the configured Databricks cluster has been deleted. In this case, you must create a new cluster and update the job configuration with the new cluster to ensure the job runs successfully.
| Cluster Details | Description |
|---|---|
| Choose Cluster | Provide a name for the job cluster that you want to create. |
| Job Configuration Name | Provide a name for the job cluster configuration. |
| Databricks Runtime Version | Select the appropriate Databricks version. |
| Worker Type | Select the worker type for the job cluster. |
| Workers |
Enter the number of workers to be used for running the job in the job cluster. You can either have a fixed number of workers or you can choose autoscaling. |
| Enable Autoscaling | Autoscaling helps in scaling up or down the number of workers within the range specified by you. This helps in reallocating workers to a job during its compute-intensive phase. Once the compute requirement reduces the excess number of workers are removed. This helps control your resource costs. |
| Cloud Infrastructure Details | |
| First on Demand |
Provide the number of cluster nodes that are marked as first_on_demand. The first_on_demand nodes of the cluster are placed on on-demand instances. |
| Availability |
Choose the type of EC2 instances to launch your Apache Spark clusters, from the following options:
|
| Zone |
Identifier of the availability zone or data center in which the cluster resides. The provided availability zone must be in the same region as the Databricks deployment. |
| Instance Profile ARN | Provide an instance profile ARN that can access the target Amazon S3 bucket. |
| EBS Volume Type | The type of EBS volume that is launched with this cluster. |
| EBS Volume Count | The number of volumes launched for each instance of the cluster. |
| EBS Volume Size | The size of the EBS volume to be used for the cluster. |
| Additional Details | |
| Spark Config | To fine tune Spark jobs, provide custom Spark configuration properties in key value pairs. |
| Environment Variables | Configure custom environment variables that you can use in init scripts. |
| Logging Path (DBFS Only) | Provide the logging path to deliver the logs for the Spark jobs. |
| Init Scripts | Provide the init or initialization scripts that run during the start up of each cluster. |
You can configure the SQS and SNS services to send notifications related to the node in this job. This provides information about various events related to the node without actually connecting to the Calibo Accelerate platform.
| SQS and SNS |
|---|
| Configurations - Select an SQS or SNS configuration that is integrated with the Calibo Accelerate platform. |
|
Events - Enable the events for which you want to enable notifications:
|
| Event Details - Select the details of the events from the dropdown list, that you want to include in the notifications. |
| Additional Parameters - Provide any additional parameters that are to be added in the SQS and SNS notifications. A sample JSON is provided, you can use this to write logic for processing the events. |
| What's next? Data Ingestion from Data Catalogs to Unity Catalog |